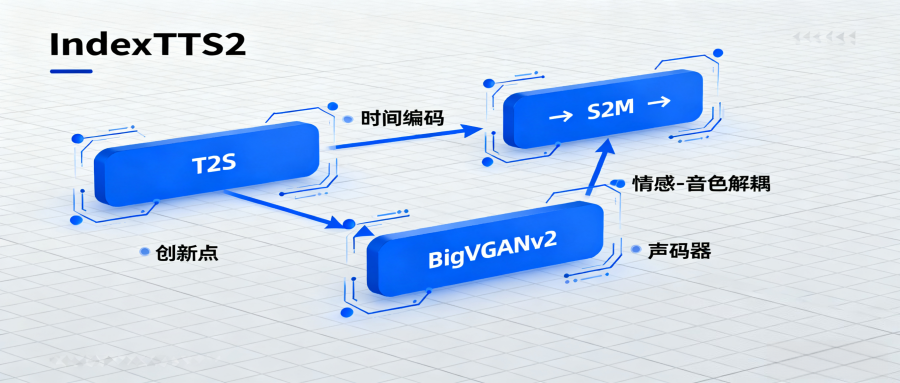
IndexTTS2 是哔哩哔哩(B 站)Index 团队开源的新一代声音克隆大模型,也是首个支持精确时长控制的自回归零样本文本转语音(TTS)系统,这与传统语音合成系统有了明显区别,解决了传统语音合成模型难以在保持自然韵律的同时精确控制时长的难题,由Text-to-Semantic(T2S)、Semantic-to-Mel(S2M)以及BigVGANv2声码器三个核心模块组成,IndexTTS-2.0的精准时长控制使其特别适合视频配音,大家可以指定生成特定时长的语音,确保与画面严格同步,B站甚至已将其应用于“AI原声翻译”功能,能够完美还原UP主的声线、音色、气口,生成更自然的外语配音,数字人虚拟主播还可以借助IndexTTS-2.0实现情感可控的语音驱动,让声音表现更加自然生动,字节律动提供最新版本的本地部署安装的INDEXTTS2官网下载。
IndexTTS-2.0的问世标志着零样本TTS进入“情感可控+时长精确”的双维度时代。它不仅解决了自回归语音合成时长不可控的历史难题,还通过音色与情感分离,实现了前所未有的控制灵活性,对于内容创作者、开发者和企业用户来说,IndexTTS-2.0开源模型的出现,大大降低了高质量语音合成的门槛,将推动语音交互应用进入全新的发展阶段,这项技术已经开始重塑配音、内容创作和语音交互的体验边界,未来无疑将在更多场景中发挥其独特价值。
IndexTTS2具有以下厉害之处:
- 精准时长控制:IndexTTS2 凭借 “时间编码机制” 与 “灵活时长模式” 两大核心技术,首次在自回归 TTS 架构中实现了毫秒级精准时长控制。它提供可控模式和自由模式两种时长控制模式,可控模式下用户可直接指定目标时长比例或具体 token 数量,在 SeedTTS 测试集上,0.75 倍速至 1.25 倍速的时长误差率低于 0.07%;自由模式下模型可自动复刻参考音频的原始节奏,保持情感自然。
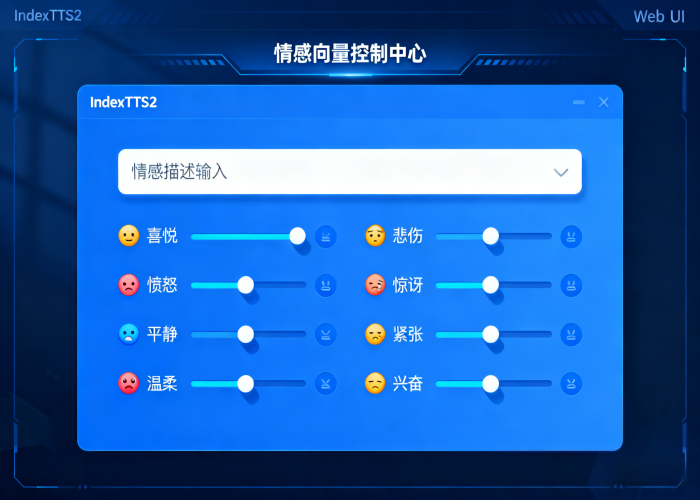
- 情感与音色分离建模:该模型通过引入对比学习的情感编码器和说话人特征提取器,实现了情感表达与音色特征的彻底解耦。用户可以独立控制情感和音色,例如用一段音频保留音色,再用另一段不同情感的音频或文本描述赋予情绪,在零样本条件下,模型能精准还原目标音色并完全重现指定情绪。

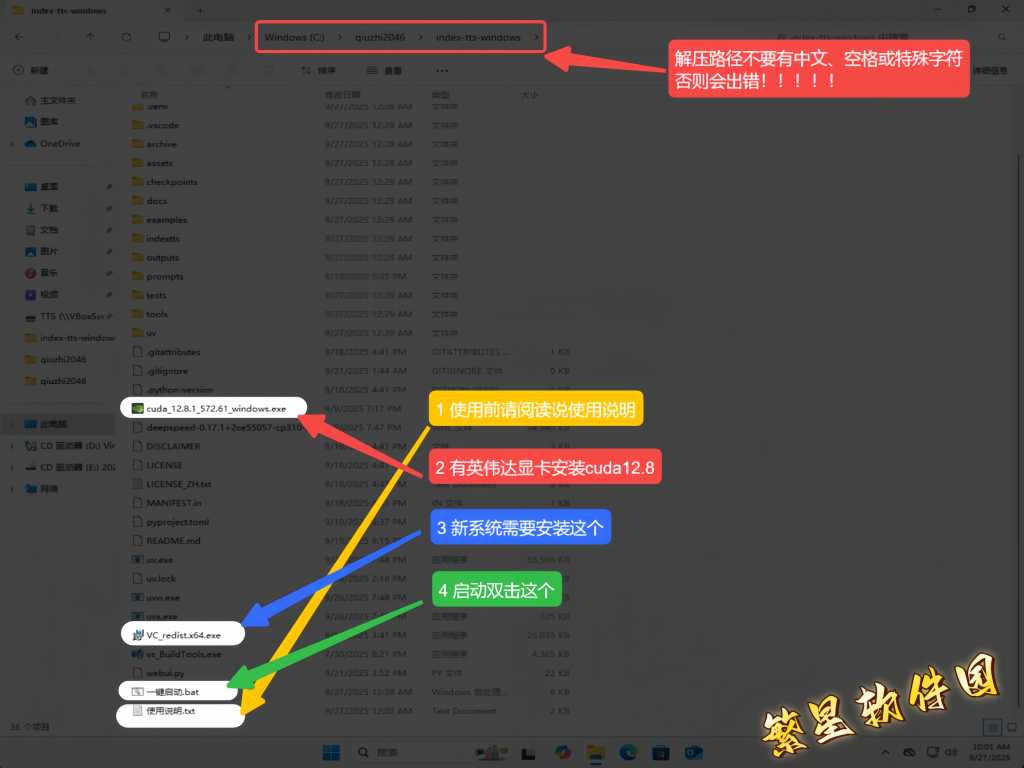
下载地址
下载地址1:https://pan.quark.cn/s/64c1f633b064
下载地址2:https://pan.baidu.com/s/1YwOq9Gv_JAq1CDrtJB9lTQ?pwd=9981

 字节律动
字节律动